
本次开发环境为:
系统:Windows 10 10.0
JDK:JRE: 1.8.0_152-release-1136-b43 amd64 JVM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
开发工具:IntelliJ IDEA 2018.1.8
springboot框架:2.2.0
直接上干货,不多废话,相关问题欢迎在评论区指教。
1、首先准备本次会用到的相关jar包,在pom.xml中导入
<!-- xss过滤组件 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
<!-- StringUtil工具类-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.9</version>
</dependency>
2、开始制作一个字符串过滤工具,使其所有字符串都能按照相同规则进行过滤
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.safety.Whitelist;
/**
* 类 {@code FilterCoreUtil} 用于Xss非法标签过滤工具类 <br> 过滤html中的xss字符.
*
* 本软件仅对本次教程负责,版权所有 <a href="http://www.cnhuashao.com">中国,華少</a><br>
*
* @author cnHuaShao
* <a href="mailto:lz2392504@gmail.com
* <p>
* ">cnHuaShao</a>
* 修改备注:
* @version v1.0.1 2019/11/5 19:42
*/
public class FilterCoreUtil {
/**
* 使用自带的basicWithImages 白名单
* 允许的便签有a,b,blockquote,br,cite,code,dd,dl,dt,em,i,li,ol,p,pre,q,small,span,
* strike,strong,sub,sup,u,ul,img
* 以及a标签的href,img标签的src,align,alt,height,width,title属性
*/
private static final Whitelist WHITE_LIST = Whitelist.basicWithImages();
/** 配置过滤化参数,不对代码进行格式化 */
private static final Document.OutputSettings OUTPUT_SETTINGS = new Document.OutputSettings().prettyPrint(false);
static {
// 富文本编辑时一些样式是使用style来进行实现的
// 比如红色字体 style="color:red;"
// 所以需要给所有标签添加style属性
WHITE_LIST.addAttributes(":all", "style");
}
/**
* 过滤主方法入口
* @param content 需要过滤的字符串
* @return 过滤后的字符串
*/
public static String clean(String content) {
if(StringUtils.isNotBlank(content)){
content = content.trim();
}
return Jsoup.clean(content, "", WHITE_LIST, OUTPUT_SETTINGS);
}
}
3、工具准备完毕,开始进行搭建一个仓库,用于处理所有的请求相关字符串
import com.cnhuashao.rapiddevelopment.core.demo4.util.FilterCoreUtil;
import org.apache.commons.lang3.StringUtils;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
/**
* 类 {@code XssHttpServletRequestWrapper} Xss核心匹配类 <br> .
*
* 本软件仅对本次教程负责,版权所有 <a href="http://www.cnhuashao.com">中国,華少</a><br>
*
* @author cnHuaShao
* <a href="mailto:lz2392504@gmail.com
* <p>
* ">cnHuaShao</a>
* 修改备注:
* @version v1.0.1 2019/11/5 19:30
*/
public class XssHttpServletRequestWrapper extends HttpServletRequestWrapper {
/**
* 需要进行过滤的请求
*/
HttpServletRequest orgRequest = null;
/**
* 是否启用过滤
*/
private boolean isIncludeRichText = false;
/**
* 深度过滤构造方法
* @param request 需要过滤的请求
* @param isIncludeRichText 是否进行过滤,默认false
*/
public XssHttpServletRequestWrapper(HttpServletRequest request, boolean isIncludeRichText) {
super(request);
orgRequest = request;
this.isIncludeRichText = isIncludeRichText;
}
/**
* 覆盖getParameter方法,将参数名和参数值都做xss过滤。<br/>
* 如果需要获得原始的值,则通过super.getParameterValues(name)来获取<br/>
* getParameterNames,getParameterValues和getParameterMap也可能需要覆盖
*/
@Override
public String getParameter(String name) {
Boolean flag = ("content".equals(name) || name.endsWith("WithHtml"));
if( flag && !isIncludeRichText){
return super.getParameter(name);
}
name = FilterCoreUtil.clean(name);
String value = super.getParameter(name);
if (StringUtils.isNotBlank(value)) {
value = FilterCoreUtil.clean(value);
}
return value;
}
@Override
public String[] getParameterValues(String name) {
String[] arr = super.getParameterValues(name);
if(arr != null){
for (int i=0;i<arr.length;i++) {
arr[i] = FilterCoreUtil.clean(arr[i]);
}
}
return arr;
}
/**
* 覆盖getHeader方法,将参数名和参数值都做xss过滤。<br/>
* 如果需要获得原始的值,则通过super.getHeaders(name)来获取<br/>
* getHeaderNames 也可能需要覆盖
*/
@Override
public String getHeader(String name) {
name = FilterCoreUtil.clean(name);
String value = super.getHeader(name);
if (StringUtils.isNotBlank(value)) {
value = FilterCoreUtil.clean(value);
}
return value;
}
/**
* 获取最原始的request
*
* @return
*/
public HttpServletRequest getOrgRequest() {
return orgRequest;
}
/**
* 获取最原始的request的静态方法
*
* @return
*/
public static HttpServletRequest getOrgRequest(HttpServletRequest req) {
if (req instanceof XssHttpServletRequestWrapper) {
return ((XssHttpServletRequestWrapper) req).getOrgRequest();
}
return req;
}
}
4、Xss处理仓库均准备妥当,下面就可以开始编写统一的拦截器了
import org.apache.commons.lang3.BooleanUtils;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 类 {@code XssFilter} Xss防止注入拦截器 <br> 用于过滤web请求中关于xss相关攻击的特定字符.
*
* 本软件仅对本次教程负责,版权所有 <a href="http://www.cnhuashao.com">中国,華少</a><br>
*
* @author cnHuaShao
* <a href="mailto:lz2392504@gmail.com
* <p>
* ">cnHuaShao</a>
* 修改备注:
* @version v1.0.1 2019/11/5 19:10
*/
public class XssFilter implements Filter {
private Logger log = LoggerFactory.getLogger(XssFilter.class);
/**
* 是否过滤富文本内容
*/
private static boolean IS_INCLUDE_RICH_TEXT = false;
/**
* 预设定白名单地址
* 将根据该变量中设置的相关目录进行直接放行操作。
*/
public List<String> excludes = new ArrayList<>();
/**
* 拦截器核心处理单元
* 用于处理所有需要过滤的请求,在此进行确认其合法性
* @param request
* @param response
* @param filterChain
* @throws IOException
* @throws ServletException
*/
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException,ServletException {
if(log.isDebugEnabled()){
log.debug("-------------------- get into xss filter --------------------");
}
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse resp = (HttpServletResponse) response;
//进行白名单过滤,如符合白名单,则直接放行
if(handleExcludeUrl(req, resp)){
filterChain.doFilter(request, response);
return;
}
//开始进行深度过滤,判定其携带参数是否合法
XssHttpServletRequestWrapper xssRequest = new XssHttpServletRequestWrapper((HttpServletRequest) request,IS_INCLUDE_RICH_TEXT);
filterChain.doFilter(xssRequest, response);
}
/**
* 白名单过滤器
* @param request 拦截的请求
* @param response 拦截的响应
* @return 是否符合白名单
*/
private boolean handleExcludeUrl(HttpServletRequest request, HttpServletResponse response) {
//白名单为空时直接返回false,使其向下执行
if (excludes == null || excludes.isEmpty()) {
return false;
}
//提取访问的URL地址
String url = request.getServletPath();
log.info("开始进行过滤{} {}",new Date(),url);
//开始根据白名单地址进行判定,如符合则直接放行
for (String pattern : excludes) {
Pattern p = Pattern.compile("^" + pattern);
Matcher m = p.matcher(url);
if (m.find()) {
return true;
}
}
return false;
}
/**
* 初始化拦截器配置
* @param filterConfig
* @throws ServletException
*/
@Override
public void init(FilterConfig filterConfig) throws ServletException {
if(log.isDebugEnabled()){
log.debug("----------------- xss filter init -----------------");
}
//获取其初始化时预设置的深度过滤开关,根据其预设的true、false进行确定其是否开启深度拦截
String isIncludeRichText = filterConfig.getInitParameter("isIncludeRichText");
if(StringUtils.isNotBlank(isIncludeRichText)){
IS_INCLUDE_RICH_TEXT = BooleanUtils.toBoolean(isIncludeRichText);
}
//获取其初始化时预设置的白名单字符串,根据【,】符号进行截取存储。
String temp = filterConfig.getInitParameter("excludes");
if (temp != null) {
String[] url = temp.split(",");
for (int i = 0; url != null && i < url.length; i++) {
excludes.add(url[i]);
}
}
}
}
5、添加cookie拦截器
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.servlet.*;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.Date;
/**
* 类 {@code CookieFilter} 会话Cookie拦截 <br> 用于对所有web会话的Cookie进行安全检查.
*
* 本软件仅对本次教程负责,版权所有 <a href="http://www.cnhuashao.com">中国,華少</a><br>
*
* @author cnHuaShao
* <a href="mailto:lz2392504@gmail.com
* <p>
* ">cnHuaShao</a>
* 修改备注:
* @version v1.0.1 2019/11/5 20:10
*/
public class CookieFilter implements Filter{
private static final Logger log = LoggerFactory.getLogger(CookieFilter.class);
/**
* 继承方法,拦截器初始化逻辑
* @param filterConfig
* @throws ServletException
*/
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
/**
* 自定义拦截器,用于Cookie全局设置
* @param request 请求
* @param response 响应
* @param chain filterchain是servlet容器提供给开发人员的对象
* @throws IOException
* @throws ServletException
*/
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse resp = (HttpServletResponse) response;
//日志打印
if(log.isDebugEnabled()){
String url = req.getServletPath();
log.debug("-------- get into Cookie filter {} {}",new Date(),url);
}
//获取请求中的cookies
Cookie[] cookies = req.getCookies();
//如果不为空,则开始对其中的所有cookie进行设置
if (cookies!=null){
for (Cookie cookie : cookies){
if (cookie!=null){
//设置cookie最大有效期,单位秒,当前设置一小时60*60
cookie.setMaxAge(3600);
//向浏览器指定,只允许https协议下才可以发送cookie
cookie.setSecure(true);
//设置cookie只能使用
cookie.setHttpOnly(true);
resp.addCookie(cookie);
}
}
}
//请求下发
chain.doFilter(req,resp);
}
/**
* 继承方法,在销毁filter时进行的操作
*/
@Override
public void destroy() {
}
}
6、所有拦截器准备就绪,在其SpringBoot启动时进行加载
import com.cnhuashao.rapiddevelopment.core.demo4.filter.CookieFilter;
import com.cnhuashao.rapiddevelopment.core.demo4.filter.XssFilter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
/**
* 类 {@code XssConfig} Xss配置加载类 <br> 用于将Xss拦截器在系统初始时加载至web服务器中.
* 本软件仅对本次教程负责,版权所有 <a href="http://www.cnhuashao.com">中国,華少</a><br>
*
* @author cnHuaShao
* <a href="mailto:lz2392504@gmail.com
* <p>
* ">cnHuaShao</a>
* 修改备注:
* @version v1.0.1 2019/11/5 20:12
*/
@Configuration
public class XssConfig {
private Logger log = LoggerFactory.getLogger(XssConfig.class);
/**
* cookie拦截器
* 用于Cookie全局设置,主要设置有效期、https安全访问、httpOnly启用
* @return
*/
@Bean
public FilterRegistrationBean cookieFilterRegistrationBean(){
log.info("------------ Start Cookie Filter ------------");
//1、启动拦截器
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
//注册Cookie拦截器
filterRegistrationBean.setFilter(new CookieFilter());
//设置bean加载顺序
filterRegistrationBean.setOrder(1);
//启用注册
filterRegistrationBean.setEnabled(true);
//添加URL为全部,使其拦截器全局拦截
filterRegistrationBean.addUrlPatterns("/*");
return filterRegistrationBean;
}
/**
* 配置初始全局拦截器Xss过滤器
* @return FilterRegistrationBean
*/
@Bean
public FilterRegistrationBean xssFilterRegistrationBean() {
log.info("------------ Start Xss Filter ------------");
//1、启动拦截器
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
//注册Xss拦截器
filterRegistrationBean.setFilter(new XssFilter());
//设置bean加载顺序
filterRegistrationBean.setOrder(1);
//启用注册
filterRegistrationBean.setEnabled(true);
//添加URL为全部,使其拦截器全局拦截
filterRegistrationBean.addUrlPatterns("/*");
//2、设置初始化方法
Map<String, String> initParameters = new HashMap<String,String>(2);
//设置白名单
initParameters.put("excludes", "/static/*,/img/*,/js/*,/css/*");
//是否启用深度过滤机制(文本过滤机制),默认fales
initParameters.put("isIncludeRichText", "true");
//为此注册设置init参数。调用此方法将替换任何*现有的init参数。
filterRegistrationBean.setInitParameters(initParameters);
return filterRegistrationBean;
}
}
7、进行测试拦截器效果
继续访问上一篇的地址:http://127.0.0.1:8081/hello?name=cnHuaShao
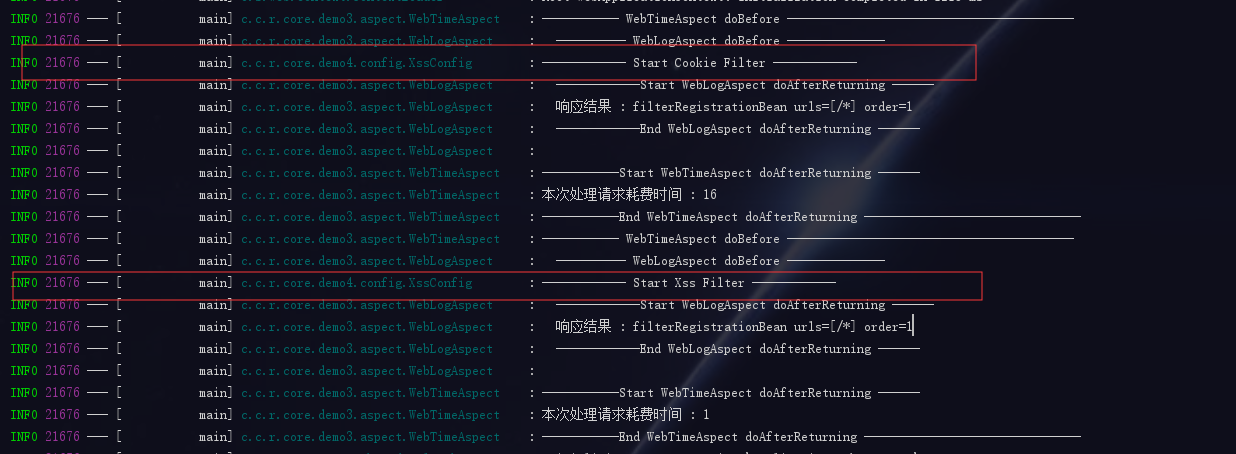
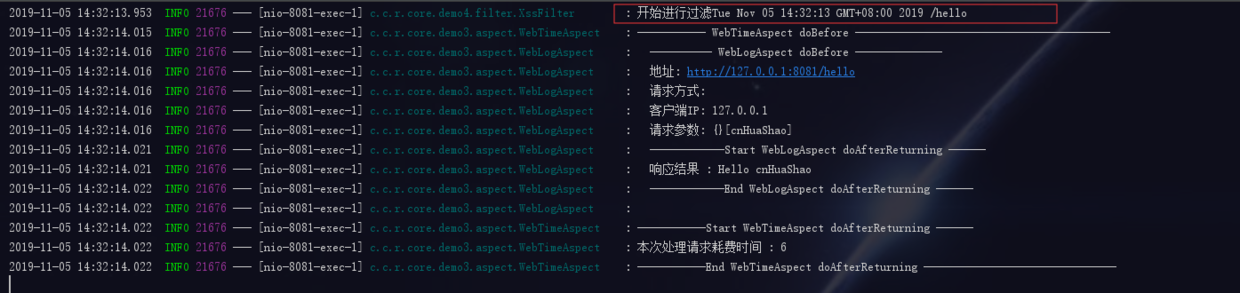
拦截器已成功过滤,至此我们所有的web请求均会经过该拦截器进行过滤,日常调配时只需要在拦截器类中进行配置即可
代码示例
本文的相关例子可以查看仓库中的RapidDevelopment-demo3目录:
Gitee 地址
如果您觉得本文不错,欢迎Star支持
本文声明:

知识共享许可协议
本作品由 cn華少 采用 知识共享署名-非商业性使用 4.0 国际许可协议 进行许可。